Содержание
Шифры замены
В шифрах замены (или шифрах подстановки), в отличие от перестановочных шифров, элементы текста не меняют свою последовательность, а изменяются сами, т.е. происходит замена исходных букв на другие буквы или символы (один или несколько) по неким правилам.
На этой страничке описаны шифры, в которых замена происходит на буквы или цифры. Когда же замена происходит на какие-то другие не буквенно-цифровые символы, на комбинации символов или рисунки, это называют прямым кодированием.
Моноалфавитные шифры
В шифрах с моноалфавитной заменой каждая буква заменяется на одну и только одну другую букву/символ или группу букв/символов. Если в алфавите 33 буквы, значит есть 33 правила замены: на что менять А, на что менять Б и т.д.
Такие шифры довольно легко расшифровать даже без знания ключа. Делается это при помощи частотного анализа зашифрованного текста - надо посчитать, сколько раз каждая буква встречается в тексте, и затем поделить на общее число букв. Получившуюся частоту надо сравнить с эталонной. Самая частая буква для русского языка - это буква О, за ней идёт Е и т.д. Правда, работает частотный анализ на больших литературных текстах. Если текст маленький или очень специфический по используемым словам, то частотность букв будет отличаться от эталонной, и времени на разгадывание придётся потратить больше. Ниже приведена таблица частотности букв (то есть относительной частоты встречаемых в тексте букв) русского языка, рассчитанная на базе НКРЯ.
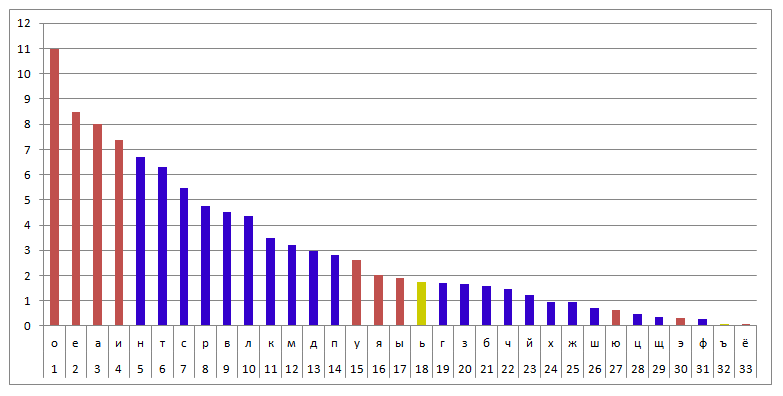

Использование метода частотного анализа для расшифровки шифрованных сообщений красиво описано во многих литературных произведениях, например, у Артура Конана Дойля в романе «Пляшущие человечки» или у Эдгара По в «Золотом жуке».
Составить кодовую таблицу для шифра моноалфавитной замены легко, но запомнить её довольно сложно и при утере восстановить практически невозможно, поэтому обычно придумывают какие-то правила составления таких кодовых страниц. Ниже приведены самые известные из таких правил.
Случайный код
Как я уже писал выше, в общем случае для шифра замены надо придумать, какую букву на какую надо заменять. Самое простое - взять и случайным образом перемешать буквы алфавита, а потом их выписать под строчкой алфавита. Получится кодовая таблица. Например, вот такая:

Число вариантов таких таблиц для 33 букв русского языка = 33! ≈ 8.683317618811886*1036. С точки зрения шифрования коротких сообщений - это самый идеальный вариант: чтобы расшифровать, надо знать кодовую таблицу. Перебрать такое число вариантов невозможно, а если шифровать короткий текст, то и частотный анализ не применишь.
Но для использования в квестах такую кодовую таблицу надо как-то по-красивее преподнести. Разгадывающий должен для начала эту таблицу либо просто найти, либо разгадать некую словесно-буквенную загадку. Например, отгадать ключевое слово или решить лабиринт-алфавит.
Ключевое слово
Один из вариантов составления кодовой таблицы - использование ключевого слова. Записываем алфавит, под ним вначале записываем ключевое слово, состоящее из неповторяющихся букв, а затем выписываем оставшиеся буквы. Например, для слова «манускрипт» получим вот такую таблицу:

Как видим, начало таблицы перемешалось, а вот конец остался неперемешенным. Это потому, что самая «старшая» буква в слове «манускрипт» - буква «У», вот после неё и остался неперемешенный «хвост». Буквы в хвосте останутся незакодированными. Можно оставить и так (так как большая часть букв всё же закодирована), а можно взять слово, которое содержит в себе буквы А и Я, тогда перемешаются все буквы, и «хвоста» не будет.
Само же ключевое слово можно предварительно тоже загадать, например при помощи ребусов или рамок. Например, вот так:

Разгадав арифметический ребус-рамку и сопоставив буквы и цифры зашифрованного слова, затем нужно будет получившееся слово вписать в кодовую таблицу вместо цифр, а оставшиеся буквы вписать по-порядку. Получится вот такая кодовая таблица:

Атбаш
Изначально шифр использовался для еврейского алфавита, отсюда и название. Слово атбаш (אתבש) составлено из букв «алеф», «тав», «бет» и «шин», то есть первой, последней, второй и предпоследней букв еврейского алфавита. Этим задаётся правило замены: алфавит выписывается по порядку, под ним он же выписывается задом наперёд. Тем самым первая буква кодируется в последнюю, вторая - в предпоследнюю и т.д.


Фраза «ВОЗЬМИ ЕГО В ЭКСЕПШН» превращается при помощи этого шифра в «ЭРЧГТЦ ЪЬР Э ВФНЪПЖС».
Гласные-согласные
Для составления кодовой таблицы нужно сначала написать алфавит по порядку, а затем под ним выписать сначала гласные, а затем все остальные буквы. Получится вот такая таблица.

ROT1
Этот шифр известен многим детям. Ключ прост: каждая буква заменяется на следующую за ней в алфавите. Так, A заменяется на Б, Б на В и т.д., а Я заменяется на А. «ROT1» значит «ROTate 1 letter forward through the alphabet» (англ. «поверните/сдвиньте алфавит на одну букву вперед»). Сообщение «Хрюклокотам хрюклокотамит по ночам» станет «Цсялмплпубн цсялмплпубнйу рп опшбн». ROT1 весело использовать, потому что его легко понять даже ребёнку, и легко применять для шифрования. Но его так же легко и расшифровать.
Онлайн-калькулятор всех русских РОТ-шифров


ROT3 или Шифр Цезаря
Шифр Цезаря — один из древнейших шифров. При шифровании каждая буква заменяется другой, отстоящей от неё в алфавите не на одну, а на большее число позиций. Шифр назван в честь римского императора Гая Юлия Цезаря, использовавшего его для секретной переписки. Он использовал сдвиг на три буквы (ROT3). Шифрование для русского алфавита многие предлагают делать с использованием такого сдвига:
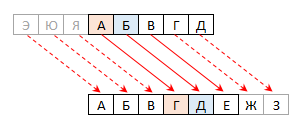
Я всё же считаю, что в русском языке 33 буквы, поэтому предлагаю вот такую кодовую таблицу:

Интересно, что в этом варианте в алфавите замены читается фраза «где ёж?», поэтому можно используя эту фразу, «намекнуть» разгадывающему на применённый способ шифрования :)

Но сдвиг ведь можно делать на произвольное число букв - от 1 до 33. Поэтому для удобства можно сделать диск, состоящий из двух колец, вращающихся относительно друг друга на одной оси, и написать на кольцах в секторах буквы алфавита. Тогда можно будет иметь под рукой ключ для кода Цезаря с любым смещением. А можно совместить на таком диске с вращающимися частями шифр Цезаря с атбашем, и получится что-то вроде этого:

Собственно, поэтому такие шифры и называются ROT - от английского слова «rotate» - «вращать».
ROT5
В этом варианте кодируются только цифры, остальной текст остаётся без изменений. Производится 5 замен, поэтому и ROT5: 0↔5, 1↔6, 2↔7, 3↔8, 4↔9.
ROT13
ROT13 — это вариация шифра Цезаря для латинского алфавита со сдвигом на 13 символов. Его часто применяют в интернете в англоязычных форумах как средство для сокрытия спойлеров, основных мыслей, решений загадок и оскорбительных материалов от случайного взгляда.
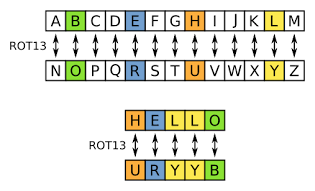
Латинский алфавит из 26 букв делится на две части. Вторая половина записывается под первой. При кодировании буквы из верхней половины заменяются на буквы из нижней половины и наоборот.
ROT18
Всё просто. ROT18 - это комбинация ROT5 и ROT13 :)
ROT47
Существует более полный вариант этого шифра - ROT47. Вместо использования алфавитной последовательности A–Z, ROT47 использует больший набор символов, почти все отображаемые символы из первой половины ASCII-таблицы. При помощи этого шифра можно легко кодировать url, e-mail, и будет непонятно, что это именно url и e-mail :)
Например, ссылка на этот текст https://nzdr.ru/games/quest/crypt/cipher/zamena?&#rot47 зашифруется вот так:
9EEADi^^?K5C]CF^82>6D^BF6DE^4CJAE^4:A96C^K2>6?2nURC@Ecf. Только опытный разгадывальщик по повторяющимся в начале текста двойкам символов сможет додуматься, что 9EEADi^^ может означать https:⁄⁄.

Квадрат Полибия
Полибий - греческий историк, полководец и государственный деятель, живший в III веке до н.э. Он предложил оригинальный код простой замены, который стал известен как «квадрат Полибия» (англ. Polybius square) или шахматная доска Полибия. Данный вид кодирования изначально применялся для греческого алфавита, но затем был распространен на другие языки. Буквы алфавита вписываются в квадрат или подходящий прямоугольник. Если букв для квадрата больше, то их можно объединять в одной ячейке.
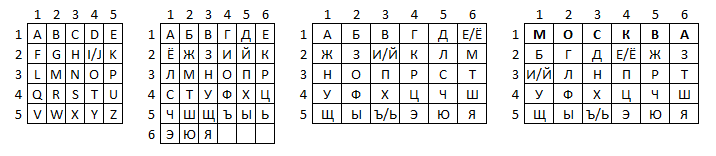
Такую таблицу можно использовать как в шифре Цезаря. Для шифрования на квадрате находим букву текста и вставляем в шифровку нижнюю от неё в том же столбце. Если буква в нижней строке, то берём верхнюю из того же столбца. Для кириллицы можно использовать таблицу РОТ11 (аналог шифра Цезаря со сдвигом на 11 символов):
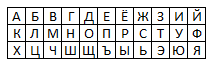
Буквы первой строки кодируются в буквы второй, второй - в третью, а третьей - в первую.
Но лучше, конечно, использовать «фишку» квадрата Полибия - координаты букв:
- Под каждой буквой кодируемого текста записываем в столбик две координаты (верхнюю и боковую). Получится две строки. Затем выписываем эти две строки в одну строку, разбиваем её на пары цифр и используя эти пары как координаты, вновь кодируем по квадрату Полибия.
- Можно усложнить. Исходные координаты выписываем в строку без разбиений на пары, сдвигаем на нечётное количество шагов, разбиваем полученное на пары и вновь кодируем.
Квадрат Полибия можно создавать и с использованием кодового слова. Сначала в таблицу вписывается кодовое слово, затем остальные буквы. Кодовое слово при этом не должно содержать повторяющихся букв.
Вариант шифра Полибия используют в тюрьмах, выстукивая координаты букв - сначала номер строки, потом номер буквы в строке.
Ниже приведён пример настоящего шифра, использовавшегося польскими шпионами в СССР накануне войны. В нём использован классический квадрат Полибия, но усложнена методика кодирования номеров столбцов и строк. За счёт такого усложнения становится невозможным применить частотный анализ для декодирования.

Стихотворный шифр
Этот метод шифрования похож на шифр Полибия, только в качестве ключа используется не алфавит, а стихотворение, которое вписывается построчно в квадрат заданного размера (например, 10×10). Если строка не входит, то её «хвост» обрезается или переносится на другую строку. Далее полученный квадрат используется для кодирования текста побуквенно двумя координатами, как в квадрате Полибия. Например, берём хороший стих «Бородино» Лермонтова и заполняем таблицу. Замечаем, что букв Ё, Й, Х, Ш, Щ, Ъ, Э в таблице нет, а значит и зашифровать их мы не сможем. Буквы, конечно, редкие и могут не понадобиться. Но если они всё же будут нужны, придётся выбирать другой стих, в котором есть все буквы.
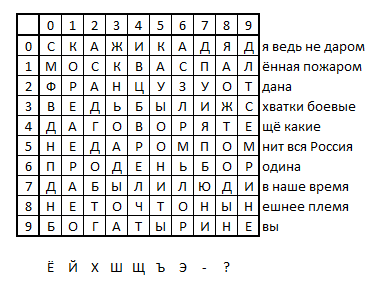
Такая большая таблица с повторяющимися буквами хороша тем, что одну и ту же букву можно зашифровать разными способами. Например, буква О встречается в ней 12 раз и может быть зашифрована 12-ю различными способами. Это существенно затрудняет расшифровку, потому что не даёт применить для декодирования частотный анализ.
Ниже приведён пример настоящего шифра, использовавшегося польскими шпионами в СССР накануне войны. В качестве текста используется начало стихотворения Кондратия Фёдоровича Рылеева "Смерть Ермака".
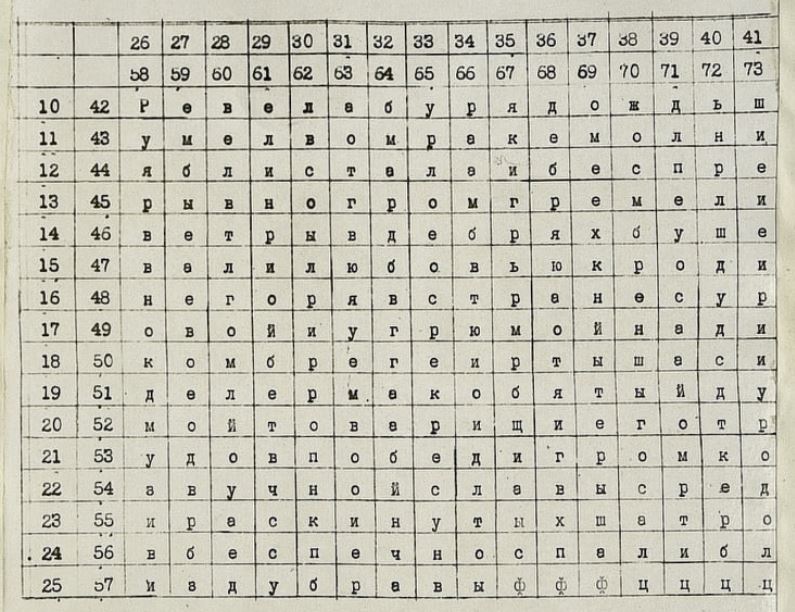
Для шифрования надо было из каждой пары чисел в любом порядке взять одно или оба числа. Например, буква Е встречается в тексте 24 раза. Самая первая Е расположена на пересечении 10,42 и 27,59. Если использовать по одному числу из пары, то эту букву Е можно было зашифровать 8-ю разными способами: 10 27, 10 59, 42 27, 42 59, 27 10, 59 10, 27 42, 59 42. И так каждую из 24-х букв Е. Итого 192 разных способа зашифровать букву Е. И это если брать только одно число из пары. Если же брать по два, то число вариантов увеличится. Частотный анализ тут будет бессилен.
Не зная текста и способа расставления чисел в кодовой таблице расшифровать такой шифр невозможно. При этом саму кодовую таблицу довольно легко запомнить.
РУС/LAT
Наверное, самый часто встречающийся шифр :) Если пытаться писать по-русски, забыв переключиться на русскую раскладку, то получится что-то типа этого: Tckb gsnfnmcz gbcfnm gj-heccrb? pf,sd gthtrk.xbnmcz yf heccre. hfcrkflre? nj gjkexbncz xnj-nj nbgf 'njuj^ Ну чем не шифр? Самый что ни на есть шифр замены. В качестве кодовой таблицы выступает клавиатура.

Таблица перекодировки выглядит вот так:

ЙЦУКЕН
На основе клавиатуры можно придумать и другую таблицу перекодировки. В кодовой её части выписаны по порядку буквы с классической клавиатуры с русской раскладкой.

Литорея
Литорея (от лат. littera — буква) — тайнописание, род шифрованного письма, употреблявшегося в древнерусской рукописной литературе. Известна литорея двух родов: простая и мудрая. Простая, иначе называемая тарабарской грамотой, заключается в следующем. Если «е» и «ё» считать за одну букву, то в русском алфавите остаётся тридцать две буквы, которые можно записать в два ряда — по шестнадцать букв в каждом:

Получится русский аналог шифра ROT13 — РОТ16 :) При шифровке верхнюю букву меняют на нижнюю, а нижнюю — на верхнюю. Ещё более простой вариант литореи — оставляют только двадцать согласных букв:
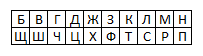
Получается шифр РОТ10. При шифровании меняют только согласные, а гласные и остальные, не попавшие в таблицу, оставляют как есть. Получается что-то типа «словарь → лсошамь» и т.п.
Мудрая литорея предполагает более сложные правила подстановки. В разных дошедших до нас вариантах используются подстановки целых групп букв, а также числовые комбинации: каждой согласной букве ставится в соответствие число, а потом совершаются арифметические действия над получившейся последовательностью чисел. Но это уже не шифр замены, а нечто более сложное - комбинированный шифр.
Шифрование биграммами
Шифр Плейфера
Шифр Плейфера - ручная симметричная техника шифрования, в которой впервые использована замена биграмм. Изобретена в 1854 году Чарльзом Уитстоном. Шифр предусматривает шифрование пар символов (биграмм), вместо одиночных символов, как в шифре подстановки и в более сложных системах шифрования Виженера. Таким образом, шифр Плейфера более устойчив к взлому по сравнению с шифром простой замены, так как затрудняется частотный анализ.
Шифр Плейфера использует таблицу 5х5 (для латинского алфавита, для русского алфавита необходимо увеличить размер таблицы до 6х6), содержащую ключевое слово или фразу. Для создания таблицы и использования шифра достаточно запомнить ключевое слово и четыре простых правила. Чтобы составить ключевую таблицу, в первую очередь нужно заполнить пустые ячейки таблицы буквами ключевого слова (не записывая повторяющиеся символы), потом заполнить оставшиеся ячейки таблицы символами алфавита, не встречающимися в ключевом слове, по порядку (в английских текстах обычно опускается символ «Q», чтобы уменьшить алфавит, в других версиях «I» и «J» объединяются в одну ячейку). Ключевое слово и последующие буквы алфавита можно вносить в таблицу построчно слева-направо, бустрофедоном или по спирали из левого верхнего угла к центру. Ключевое слово, дополненное алфавитом, составляет матрицу 5х5 и является ключом шифра.
Для того, чтобы зашифровать сообщение, необходимо разбить его на биграммы (группы из двух символов), например «Hello World» становится «HE LL OW OR LD», и отыскать эти биграммы в таблице. Два символа биграммы соответствуют углам прямоугольника в ключевой таблице. Определяем положения углов этого прямоугольника относительно друг друга. Затем руководствуясь следующими 4 правилами зашифровываем пары символов исходного текста:
- 1) Если два символа биграммы совпадают, добавляем после первого символа «Х», зашифровываем новую пару символов и продолжаем. В некоторых вариантах шифра Плейфера вместо «Х» используется «Q».
- 2) Если символы биграммы исходного текста встречаются в одной строке, то эти символы замещаются на символы, расположенные в ближайших столбцах справа от соответствующих символов. Если символ является последним в строке, то он заменяется на первый символ этой же строки.
- 3) Если символы биграммы исходного текста встречаются в одном столбце, то они преобразуются в символы того же столбца, находящимися непосредственно под ними. Если символ является нижним в столбце, то он заменяется на первый символ этого же столбца.
- 4) Если символы биграммы исходного текста находятся в разных столбцах и разных строках, то они заменяются на символы, находящиеся в тех же строках, но соответствующие другим углам прямоугольника.
Для расшифровки необходимо использовать инверсию этих четырёх правил, откидывая символы «Х» (или «Q») , если они не несут смысла в исходном сообщении.
Рассмотрим пример составления шифра. Используем ключ «Playfair example», выписываем уникальные буквы: PLAYFIREXM, записываем их построчно в таблицу и далее оставшиеся буквы алфавита. Наша кодировочная таблица примет вид:
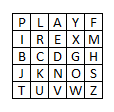
Зашифруем сообщение «Hide the gold in the tree stump». Разбиваем его на пары, не забывая про правило [1]. Получаем: «HI DE TH EG OL DI NT HE TR EX ES TU MP». Далее применяем правила [2]-[4]:
- 1. Биграмма HI формирует прямоугольник, заменяем её на BM.
- 2. Биграмма DE расположена в одном столбце, заменяем её на ND.
- 3. Биграмма TH формирует прямоугольник, заменяем её на ZB.
- 4. Биграмма EG формирует прямоугольник, заменяем её на XD.
- 5. Биграмма OL формирует прямоугольник, заменяем её на KY.
- 6. Биграмма DI формирует прямоугольник, заменяем её на BE.
- 7. Биграмма NT формирует прямоугольник, заменяем её на JV.
- 8. Биграмма HE формирует прямоугольник, заменяем её на DM.
- 9. Биграмма TR формирует прямоугольник, заменяем её на UI.
- 10. Биграмма EX находится в одной строке, заменяем её на XM.
- 11. Биграмма ES формирует прямоугольник, заменяем её на MN.
- 12. Биграмма TU находится в одной строке, заменяем её на UV.
- 13. Биграмма MP формирует прямоугольник, заменяем её на IF.
Получаем зашифрованный текст «BM ND ZB XD KY BE JV DM UI XM MN UV IF». Таким образом сообщение «Hide the gold in the tree stump» преобразуется в «BMNDZBXDKYBEJVDMUIXMMNUVIF».
Двойной квадрат Уитстона
Чарльз Уитстон разработал не только шифр Плейфера, но и другой метод шифрования биграммами, который называют «двойным квадратом». Шифр использует сразу две таблицы, размещенные по одной горизонтали, а шифрование идет биграммами, как в шифре Плейфера.
Имеется две таблицы со случайно расположенными в них алфавитами (для примера будем использовать наш алфавит).
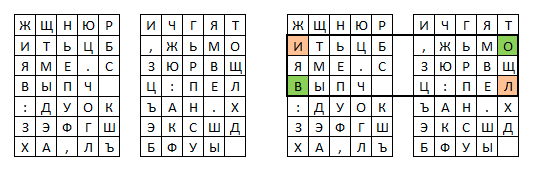
Перед шифрованием исходное сообщение разбивают на биграммы. Каждая биграмма шифруется отдельно. Первую букву биграммы находят в левой таблице, а вторую букву - в правой таблице. Затем мысленно строят прямоугольник так, чтобы буквы биграммы лежали в его противоположных вершинах. Другие две вершины этого прямоугольника дают буквы биграммы шифртекста. Предположим, что шифруется биграмма исходного текста ИЛ. Буква И находится в столбце 1 и строке 2 левой таблицы. Буква Л находится в столбце 5 и строке 4 правой таблицы. Это означает, что прямоугольник образован строками 2 и 4, а также столбцами 1 левой таблицы и 5 правой таблицы. Следовательно, в биграмму шифртекста входят буква О, расположенная в столбце 5 и строке 2 правой таблицы, и буква В, расположенная в столбце 1 и строке 4 левой таблицы, т.е. получаем биграмму шифртекста ОВ.
Если обе буквы биграммы сообщения лежат в одной строке, то и буквы шифртекста берут из этой же строки. Первую букву биграммы шифртекста берут из левой таблицы в столбце, соответствующем второй букве биграммы сообщения. Вторая же буква биграммы шифртекста берется из правой таблицы в столбце, соответствующем первой букве биграммы сообщения. Поэтому биграмма сообщения ТО превращается в биграмму шифртекста ЖБ. Аналогичным образом шифруются все биграммы сообщения:
Сообщение ПР ИЛ ЕТ АЮ _Ш ЕС ТО ГО
Шифртекст ПЕ ОВ ЩН ФМ ЕШ РФ БЖ ДЦ
Шифрование методом «двойного квадрата» дает весьма устойчивый к вскрытию и простой в применении шифр. Взламывание шифртекста «двойного квадрата» требует больших усилий, при этом длина сообщения должна быть не менее тридцати строк, а без компьютера вообще не реально.
Полиалфавитные шифры
Шифр Виженера
Естественным развитием шифра Цезаря стал шифр Виженера. В отличие от моноалфавитных это уже полиалфавитный шифр. Шифр Виженера состоит из последовательности нескольких шифров Цезаря с различными значениями сдвига. Для зашифровывания может использоваться таблица алфавитов, называемая «tabula recta» или «квадрат (таблица) Виженера». На каждом этапе шифрования используются различные алфавиты, выбираемые в зависимости от буквы ключевого слова.
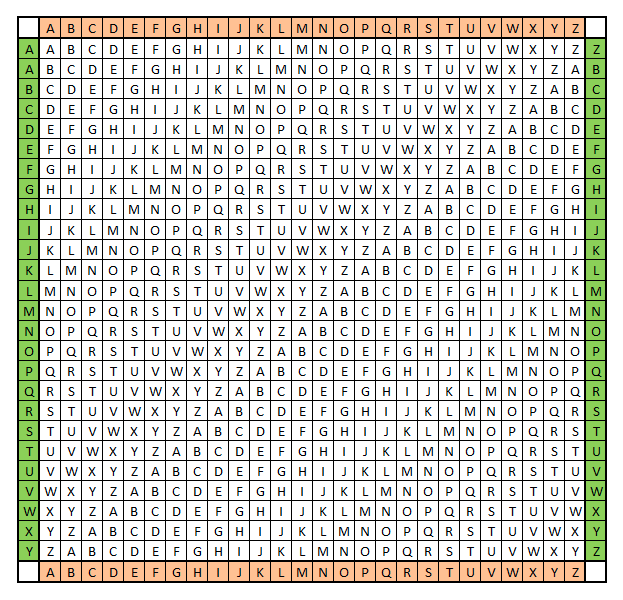
Для латиницы таблица Виженера может выглядеть вот так:
Для русского алфавита вот так:
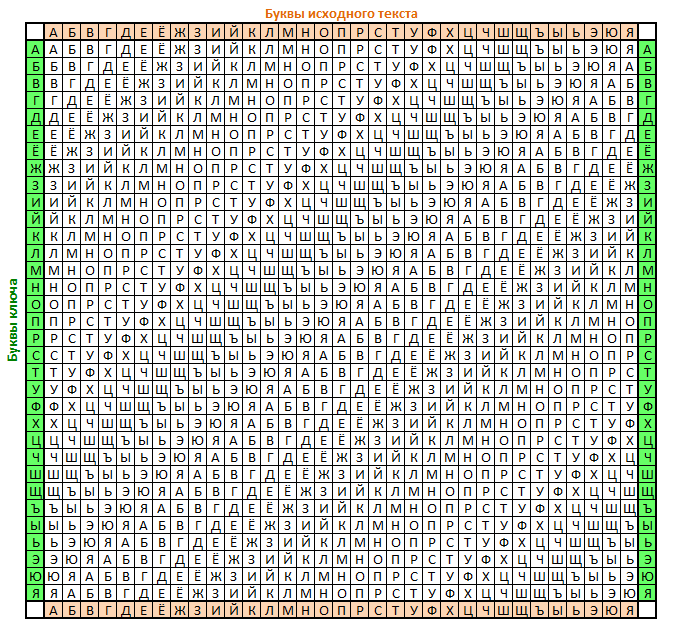
Легко заметить, что строки этой таблицы - это ROT-шифры с последовательно увеличивающимся сдвигом.
Шифруют так: под строкой с исходным текстом во вторую строку циклически записывают ключевое слово до тех пор, пока не заполнится вся строка. У каждой буквы исходного текста снизу имеем свою букву ключа. Далее в таблице находим кодируемую букву текста в верхней строке, а букву кодового слова слева. На пересечении столбца с исходной буквой и строки с кодовой буквой будет находиться искомая шифрованная буква текста.

Важным эффектом, достигаемым при использовании полиалфавитного шифра типа шифра Виженера, является маскировка частот появления тех или иных букв в тексте, чего лишены шифры простой замены. Поэтому к такому шифру применить частотный анализ уже не получится.
Для шифрования шифром Виженера можно воспользоваться Онлайн-калькулятором шифра Виженера. Для различных вариантов шифра Виженера со сдвигом вправо или влево, а также с заменой букв на числа в отсутствие компьютера можно использовать приведённые ниже таблицы:


Ниже приведён пример настоящих шифров на базе шифра Виженера, использовавшихся польскими шпионами на территории СССР перед войной.

Шифр Гронсвельда
Это вариация шифра Виженера, где вместо ключевого слова применяется ключевое число, цифры которого показывают, какой из ROT-шифров применять (на сколько позиций сдвигать букву).
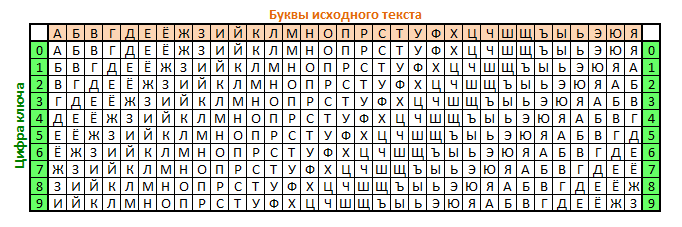
Книжный шифр
Суть метода книжного шифра - это выбор любого текста из книги, и замена каждой буквы шифруемого слова номером слова в выбранном тексте, начинающегося на нужную букву. Можно заменять не на номер слова, а на координату буквы (строка, номер в строке). При этом одной исходной букве может соответствовать несколько разных кодов, ведь одна и та же буква может находиться в разных местах. Для кодирования обычно используют страницу из какой-то заранее оговоренной книги. Без знания кодовой страницы расшифровать такие зашифрованные послания практически невозможно.
Можно использовать не конкретное издание, а какой-то классический текст, который не менялся от одного издания к другому. Например, стихотворную поэму Пушкина «Гавриилиада» или Декларацию независимости США.
Если же в качестве ключа использовать целую книгу (например, словарь), то можно зашифровывать не отдельные буквы, а целые слова и даже фразы. Тогда координатами слова будут номер страницы, номер строки и номер слова в строке. На каждое слово получится три числа. Можно также использовать внутреннюю нотацию книги - главы, абзацы и т.п. Например, в качестве кодовой книги удобно использовать Библию, ведь там есть четкое разделение на главы, и каждый стих имеет свою маркировку, что позволяет легко найти нужную строку текста. Правда, в Библии нет современных слов типа «компьютер» и «интернет», поэтому для современных фраз лучше, конечно, использовать энциклопедический или толковый словарь. Хотя если заранее договориться о некой применяемой фене, например, «смоковница» - это «компьютер», «грех» - это «байт» и т.п., то на основании Библии можно будет шифровать и современные тексты.
Это были шифры замены, в которых буквы заменяются на другие. А ещё бывают перестановочные шифры, в которых буквы не заменяются, а перемешиваются между собой.
Ссылки
- https://www.facebook.com/sergey.prudovskiy/posts/3333121743471569 - Таблицы шифров польских шпионов. 1934 год.