![]()
• Онлайн: 2

Автор: Юрий Лукач
Аннотация. В «Справочнике Веб-разработчика» кодировкам символов уделено достаточно большое внимание. Однако, вопросы читателей показывают, что необходимы дополнительные пояснения, и я счел полезным собрать основные сведения о кодировках в одном месте. Для удобства чтения эта статья разбита на две страницы.
Начнем с определения понятий. Современные компьютеры хранят всю информацию в виде двоичных байтов, т. е. 8-битовых единиц, способных принимать значение от 0 до 255. Для того, чтобы сохранить в памяти компьютера не числовую, а текстовую информацию, мы должны определить, каким байтом или байтами будет кодироваться каждый символ, который может встретиться в нашем тексте. Такое соответствие между символами и кодирующими их байтами и называется кодировкой символов (character set). Нетрудно понять, во-первых, что каждая кодировка разрабатывается для конкретного человеческого языка (точнее, для конкретной письменности), и, во-вторых, что для любого языка таких кодировок можно придумать сколько угодно. Зная человеческую натуру, нетрудно догадаться и о том, что придумают их гораздо больше, чем нужно. Естественно, так и случилось: наиболее развитая на сегодня библиотека функций перекодировки ICU (International Components for Unicode) корпорации IBM поддерживает более 170 различных кодировок.
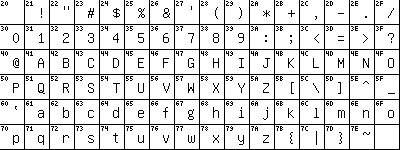
Рассмотрим подробнее кодировки тех письменностей, с которыми чаще всего сталкивается российский разработчик, т. е. латиницы и кириллицы. Для латиницы на сегодня используются две основные кодировки: ASCII и EBCDIC. ASCII (American Standard Code for Information Interchange) — это семибитная кодовая таблица (коды символов 00 - 7F или 0 - 127 десятичные), ставшая стандартом для малых и средних компьютеров, а потому и стандартом для Веба. В ней байты с шестнадцатеричными кодами 00 — 1F и 7F используются для кодирования управляющих (неотображаемых) символов, а остальные кодируют следующие символы:
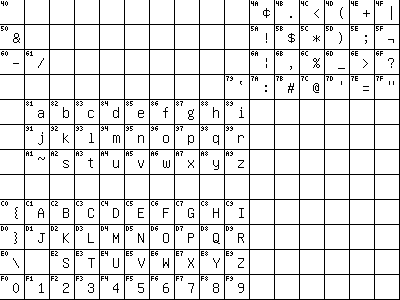
Кодировка EBCDIC (Extended Binary-Coded Decimal Interchange Code) — это восьмибитная кодировка (коды символов 00 - FF или 0 - 255 десятичные), принятая на всех компьютерах IBM, кроме PC. Можно было бы ее не упоминать, но по мере развития XML как основного формата транспорта данных в Сети мы все чаще будем сталкиваться с XML-файлами, сгенерированными на больших машинах. Здесь байты с кодами 00 — 3F кодируют управляющие символы, а остальные используются так:
Кодировки «нелатинских» алфавитных письменностей устроены следующим образом. Они кодируются восьмибитовой таблицей (1 байт = 1 символ), т. е. числами 00 - FF (0 - 255 десятичные) так, что младшая половина кодовой таблицы (коды 00 - 7F или 0 - 127 десятичные) совпадает с ASCII, а старшая половина (коды 80 - FF или 128 - 255 десятичные) содержит национальную кодировку, т. е. русские буквы в русских кодовых таблицах, турецкие в турецких и т. д. Такая организация национальных кодовых таблиц позволяет правильно отображать и обрабатывать латинские буквы, цифры и знаки препинания на любом компьютере, независимо от его системных настроек. Именно так, в частности, устроены и русские кодовые таблицы, так что мы можем в дальнейшем рассматривать только старшую их половину.
История русских кодировок — это пример неразберихи, редкостной даже для нашей компьютерной действительности. Советские стандартизирующие организации принимали ГОСТы, производители компьютеров (Apple) и операционных систем (Microsoft) их дружно игнорировали и вводили собственные кодировки. В результате мы получили наследство из четырех разных ГОСТов, две кодировки от Microsoft (для DOS и для Windows) и кодировку от Apple для Mac'ов (все, естественно, несовместимые между собой). Интересующиеся подробностями могут обратиться к странице The Cyrillic Charset Soup.
К счастью, сегодня нет нужды подробно описывать все эти кодировки, поскольку в Рунете выжили только две из них. Первая — это КОИ8-Р (КОИ означает Код для Обмена и обработки Информации, Р отличает русскую кодовую таблицу от украинской, КОИ8-У). КОИ8-Р была зарегистрирована Андреем Черновым из Релкома в качестве RFC 1489 и имеет вид:

КОИ8-Р является стандартом de facto для всех служб Интернета, кроме WWW. В частности, все службы электронной почты и новостей Рунета работают в этой кодировке. Что касается Веба, то здесь ситуация сложнее. Дело в том, что более 90% клиентских компьютеров Сети работает под управлением Windows разных версий. Windows использует собственную кодировку русских букв, которую принято назвать по номеру кодовой страницы Windows-1251 или CP1251:

Поскольку текстовые редакторы и средства разработки HTML-страниц в Windows работают в этой кодировке, абсолютное большинство Веб-документов Рунета хранится в кодировке Windows-1251.
Не следует думать, что все национальные кодировки являются байтовыми, т. е. следуют правилу: 1 символ = 1 байт. На самом деле, это справедливо только для алфавитных (буквенно-звуковых) систем письменности. С другой стороны, существуют силлабические системы письма, в которых каждый символ представляет не звук, а слог, например, индийские и дальневосточные слоговые азбуки. Поскольку слогов в языке намного больше, чем отдельных звуков, старших 128 байтов кодовой таблицы просто недостаточно для их представления. Это приводит к тому, что такие письменности используют двухбайтовые кодировки (DBCS, Double Byte Character Sets). Типичным примером такой кодировки является японская кодировка JIS, существующая в нескольких вариантах. Она охватывает латинские буквы и цифры, обе японские слоговые азбуки (катакану и хирагану) и важнейшие из китайских иероглифов. Но полноценное представление иероглифической письменности Китая, Японии и Кореи, насчитывающей несколько тысяч иероглифов, в рамках национальных кодировок остается невозможным.
Несомненным достоинством традиционных кодовых таблиц является предельная краткость представления текстовой информации. Однако, эта краткость влечет за собой и несколько недостатков, органически с ней связанных:
По мере того, как компьютеры становились мощнее, Интернет — разветвлённее, а операционные системы — дружелюбнее к пользователю, перечисленные недостатки оказывались все более серьезным препятствием на пути к созданию естественных интерфейсов «человек-компьютер» и «компьютер-Сеть». Выход из ситуации был достигнут созданием стандарта Unicode, о котором пойдет речь на следующей странице.