О кодировках символов. Часть 2. Стандарт Unicode
История стандарта
Стандарт Unicode или ISO/IEC 10646 явился результатом сотрудничества Международной организации по стандартизации (ISO) с ведущими производителями компьютеров и программного обеспечения. Причины, изложенные на предыдущей странице, привели их к принципиально новой постановке вопроса: зачем тратить усилия на развитие отдельных кодовых таблиц, если можно создать единую таблицу для всех национальных языков? Такая задача кажется излишне амбициозной, но только на первый взгляд. Дело в том, что из 6700 живых языков официальными языками государств являются около полусотни, причем пользуются они примерно 25 различными письменностями: числа для нашего компьютерного века вполне обозримые.
Предварительная прикидка показала, что для кодирования всех этих письменностей достаточно 16-битового диапазона, т. е. диапазона от 0000 до FFFF. Каждой письменности был выделен свой блок в этом диапазоне, который постепенно заполнялся кодами символов этой письменности. На сегодня кодирование всех живых официальных письменностей можно считать завершенным.
Отработанная методика анализа и описания систем письма позволила консорциуму Unicode перейти в последнее время к кодированию остальных письменностей Земли, которые представляют какой-либо интерес: это письменности мертвых языков, выпавшие из современного обихода китайские иероглифы, искуственно созданные алфавиты и т. п. Для представления всего этого богатства 16-битового кодирования уже недостаточно, и сегодня Unicode использует 21-битовое пространство кодов (000000 - 10FFFF), которое разбито на 16 зон, названных плоскостями. Пока что в планах Unicode предусмотрено использование следующих плоскостей:
- Плоскость 0 (коды 000000 - 00FFFF) — БМП, базовая многоязыковая плоскость (BMP, Basic Multilingual Plane), соответствует исходному диапазону Unicode.
- Плоскость 1 (коды 010000 - 01FFFF) — ДМП, дополнительная многоязыковая плоскость (SMP, Supplementary Multilingual Plane), предназначена для мертвых письменностей.
- Плоскость 2 (коды 020000 - 02FFFF) — ДИП, дополнительная иероглифическая плоскость (SIP, Supplementary Ideographic Plane), предназначена для иероглифов, не попавших в БМП.
- Плоскость 14 (коды 0E0000 - 0EFFFF) — ДСП, дополнительная специальная плоскость (SSP, Supplementary Special-purpose Plane), предназначена для символов специального назначения.
- Плоскость 15 (коды 0F0000 - 0FFFFF) — плоскость частного пользования (Private-Use Plane), предназначена для символов искусственных письменностей.
- Плоскость 16 (коды 100000 - 10FFFF) — плоскость частного пользования (Private-Use Plane), предназначена для символов искусственных письменностей.
Разбивка БМП на блоки приведена в WDH: Стандарт Unicode. Здесь отметим только, что первые 128 кодов (00000 - 0007F) соответствуют кодам ASCII и кодируют блок базовой латиницы. Подробно раскладка письменностей по диапазону Unicode будет описана в моей статье «Unicode и письменности мира». Поскольку нас в дальнейшем будут интересовать только символы БМП, я использую их 16-битовые коды вида XXXX (старшие биты равны нулю и не указываются).
Действующей версией стандарта является Unicode 3.1, принятый в мае 2001 г. Все подробности можно найти на официальном сайте www.unicode.org.
Общее описание
В основе Unicode лежит понятие символа (character). Символ — это абстрактное понятие, которое существует в конкретной письменности и реализуется через свои изображения (графемы). Это означает, что каждый символ задается уникальным кодом и принадлежит к конкретному блоку Unicode. Например, графема А есть и в английском, и в русском, и в греческом алфавитах. Однако, в Unicode ей соответствуют три разных символа «латинская прописная буква А» (код 0041), «кириллическая прописная буква А» (код 0410) и «греческая прописная буква АЛЬФА» (код 0391). Если мы теперь применим к этим символам преобразование в строчную букву, то соответсвенно получим «латинскую строчную букву А» (код 0061, графема a), «кириллическую строчную букву А» (код 0430, графема а) и «греческую строчную букву АЛЬФА» (код 03B1, графема α), т. е. разные графемы.
Может возникнуть вопрос: что такое преобразование в строчную букву? Здесь мы подходим к самому интересному и важному моменту в стандарте. Дело в том, что Unicode — это не просто кодовая таблица. Концепция абстрактного символа позволила создателям Unicode построить базу данных символов, в которой каждый символ описывается своим уникальным кодом (ключом базы данных), полным названием и набором свойств. Например, символ с кодом 0410 описан в этой базе так:
0410;CYRILLIC CAPITAL LETTER A;Lu;0;L;;;;;N;;;;0430;
Расшифруем эту запись. Она означает, что код 0410 присвоен «кириллической прописной букве А» (полное название символа), которая имеет следующие свойства:
| Общая категория | строчная буква (Lu = Letter, uppercase) |
| Класс сочетаний | 0 |
| Направление вывода | слева направо (L) |
| Декомпозиция символа | нет |
| Десятичная цифра | нет |
| Цифра | нет |
| Числовое значение | нет |
| Зеркальный символ | отсутствует (N) |
| Полное название в Unicode 1.0 | то же |
| Комментарий | нет |
| Отображение в прописную букву | нет |
| Отображение в строчную букву | 0430 |
| Отображение в титульную букву | нет |
Перечисленные свойства определены для каждого символа Unicode. Это позволило его разработчикам создать стандартные алгоритмы, которые определяют на основе свойств символов правила их визуализации, сортировки и преобразования в прописные/строчные буквы.
В итоге можно сказать, что стандарт Unicode состоит из трех взаимосвязанных частей:
- базы данных символов;
- базы графем (glyphs), определяющих визуальное представление этих символов;
- набора алгоритмов, определяющих правила работы с символами.
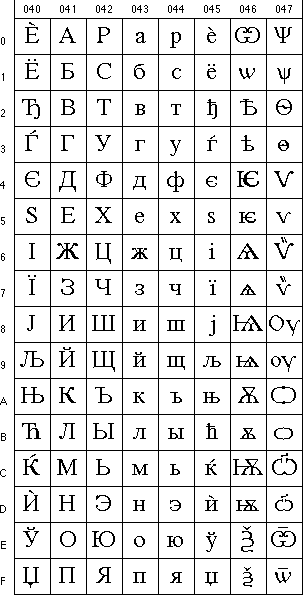
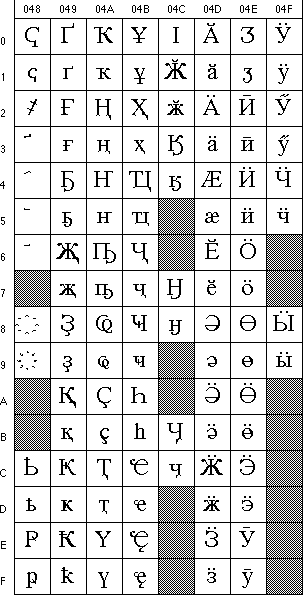
В заключение этого раздела приведем графемы блока кириллицы (коды 0400 - 04FF). Обратите внимание, что он включает в себя не только буквы современных кириллических алфавитов (русского, украинского, белорусского, болгарского, сербского, македонского и пр.), но и все буквы первоначальной кириллицы, использовавшиеся в церковнославянской письменности.
Трансформационные форматы
Как мы видели, каждый символ Unicode имеет уникальный 21-битовый код (code point). Однако, для практической реализации такая кодировка символов неудобна. Дело в том, что операционные системы и сетевые протоколы традиционно работают с данными как с потоками байтов. Это приводит, как минимум, к двум проблемам:
- Порядок байтов в слове у разных процессоров различен. Процессоры Intel, DEC и др. хранят в первом байте машинного слова его старший байт, а процессоры Motorola, Sparc и др. — младший байт. Их соответственно называют little-endian и big-endian (эти термины происходят от «остроконечников» и «тупоконечников» у Свифта, споривших о том, с какого конца нужно разбивать яйца).
- Многие байт-ориентированные системы и протоколы допускают использование в качестве данных только байтов из определенного диапазона. Остальные байты рассматриваются как служебные; в частности, нулевой байт принято использовать как символ конца строки. Поскольку Unicode кодирует символы подряд, прямая передача его кодов как цепочки байтов может войти в противоречие с правилами протокола передачи данных.
Для преодоления этих проблем стандарт включает в себя три трансформационных формата UTF-8, UTF-16 и UTF-32, которые определяют соответственно правила кодирования символов Unicode цепочками байтов, парами 16-битовых слов и 32-битовыми словами. Выбор используемого формата зависит от архитектуры вычислительной системы и стандартов хранения и передачи данных. Краткое описание трансформационных форматов можно найти в WDH: Стандарт Unicode.
Проблемы реализации
Думаю, что даже из приведенного выше краткого описания стандарта Unicode ясно, что его полная поддержка основными операционными системами будет означать революцию в области обработки текстов. Пользователь, сидящий за любым терминалом Сети, сможет выбрать любую раскладку клавиатуры, набрать текст на любом языке и передать его на любой компьютер, который правильно этот текст отобразит. Базы данных смогут хранить, правильно сортировать и выводить в отчеты текстовую информацию опять-таки на любом языке. Для того, чтобы этот рай наступил, необходимы пять вещей:
- Операционные системы должны поддерживать трансформационные форматы Unicode на уровне ввода, хранения и отображения текстовых строк.
- Необходимы «умные» драйверы клавиатур, позволяющие нам вводить символы любого блока Unicode и передающие их коды операционной системе.
- Текстовые редакторы должны поддерживать отображение всех символов Unicode и выполнять над ними общепринятый набор символьных операций.
- То же самое должно правильно выполняться СУБД в отношении текстовых и memo-полей.
- Поскольку национальные кодировки еще долгое время будут сосуществовать с Unicode, необходима поддержка преобразований текста между ними.
С сожалением приходится признать, что за десять лет (Unicode 1.0 появился в 1991 г.) в этом направлении сделано гораздо меньше, чем хотелось бы. Даже Windows, содержащая на системном уровне наиболее последовательную поддержку Unicode, полна абсолютно иррациональных ограничений, объясняемых только ее историческим развитием. В Unix ситуация еще хуже, поскольку здесь поддержка Unicode перенесена из ядра на конкретные приложения. Можно утверждать, что на сегодня наиболее серьезно Unicode поддерживается в двух средах: веб-браузерах и виртуальных Java-машинах. Это не удивительно, поскольку обе среды изначально создавались как системно-независимые.
Следует отметить и объективные трудности поддержки Unicode. Для примера остановимся только на отображении графем, для которого нужно установить в системе соответствующие шрифты. Проблема в том, что шрифт, содержащий все графемы Unicode будет иметь совершенно несуразный размер. Например, TrueType-шрифт Arial Unicode MS, содержащий большую порцию символов Unicode, «весит» 24Мб. По мере наполнения Unicode новыми блоками размер таких шрифтов приблизится к 100Мб. Выходом из положения может послужить предложенная Microsoft загрузка символов по требованию, принятая в их браузере Internet Explorer. Однако, пока стандарты о правилах формирования Unicode-шрифтов молчат.
Способы работы с символами Unicode и национальных кодировок в важнейших средах и системах программирования будут рассмотрены в следующих статьях.